

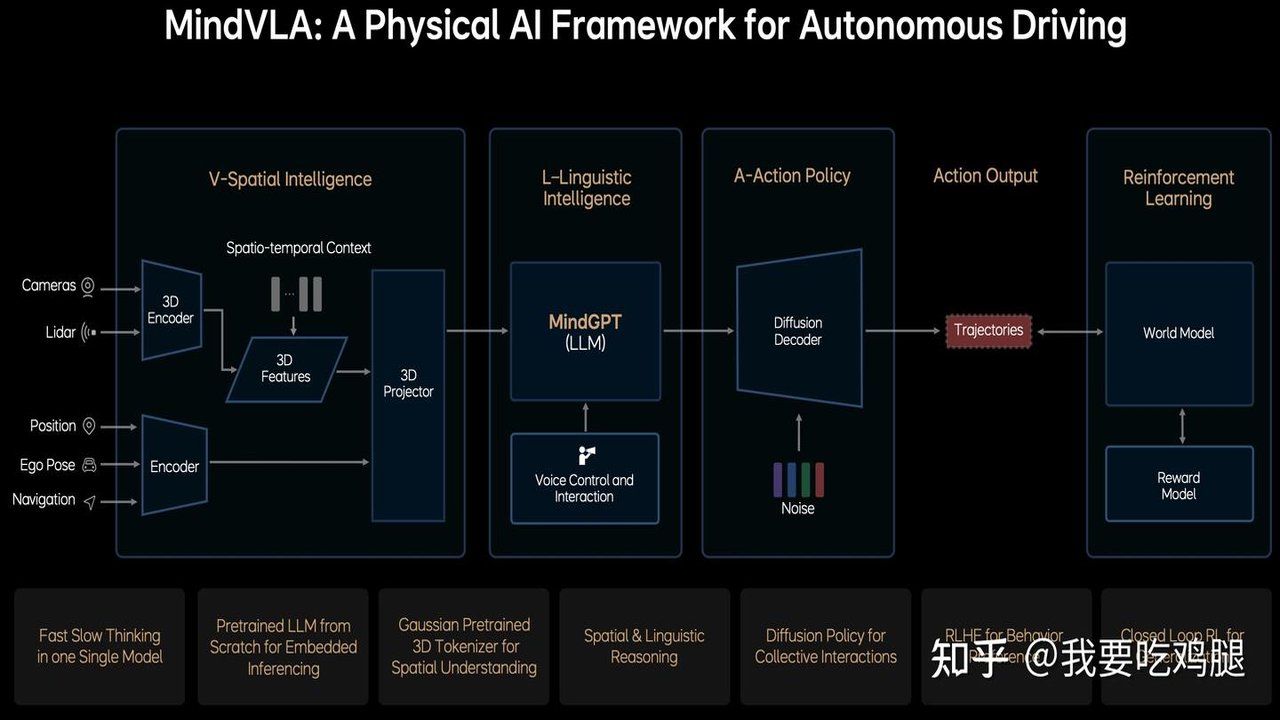




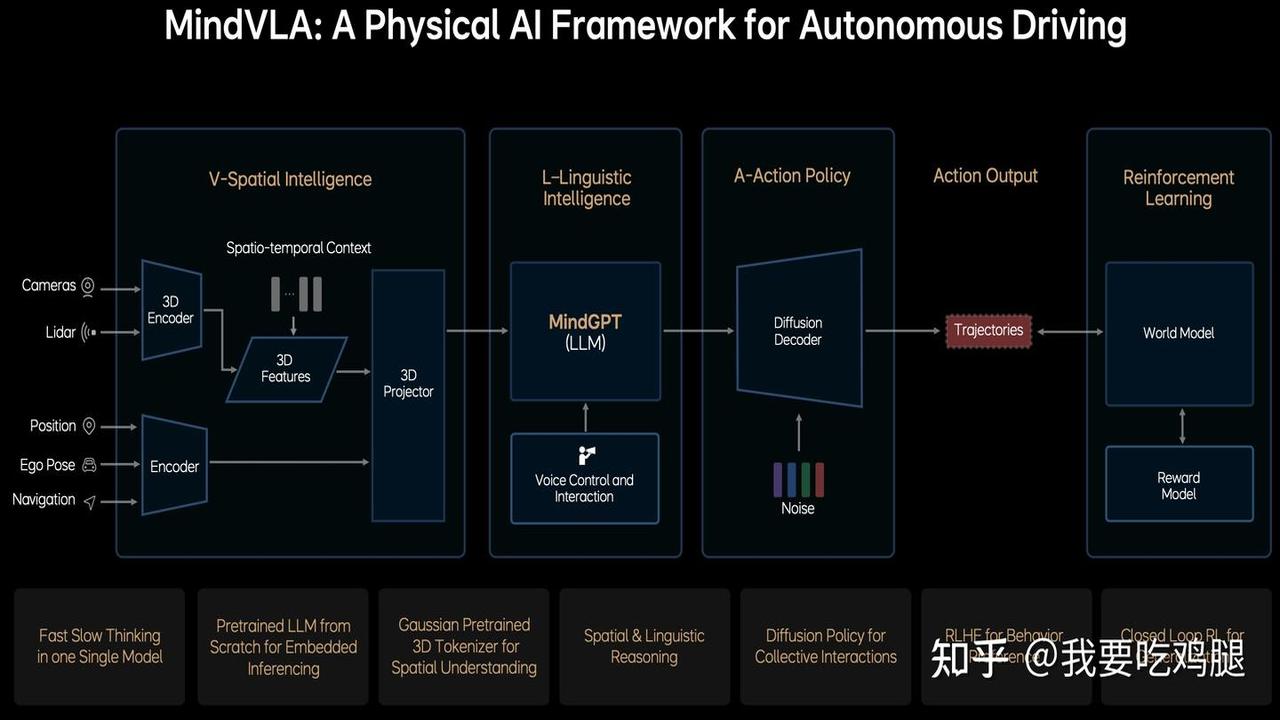
在当代语言模型的发展中,大规模参数扩展不仅提升了模型的推理能力,也将大量世界知识压缩至参数中,成为模型性能飞跃的核心。然而,将所有知识固定存储于模型参数之中既耗费资源又缺乏高效性,尤其对于计算能力有限的边缘设备而言,这种方式并不现实。


为了解决这一局限性,Hadi Pouransari、David Grangier 等研究者提出了一种结合分层记忆的语言模型架构,以及与之匹配的预训练策略。这一创新方法不仅与现有硬件生态相契合,还特别针对长尾知识存储和常见推理能力进行了优化分工。
研究团队设计了一种小型语言模型,结合拥有层级参数记忆库的增强架构。在这种设计中,小型模型负责掌握常识性知识与通用推理能力,而分层记忆库则充当外部存储,记录更为稀疏的长尾知识。在实践中,模型仅需根据上下文调用部分相关记忆块,在预训练和推断阶段将其动态添加到模型中,从而显著降低了计算资源的消耗。
通过在万亿级别的预训练数据上进行实验,该团队展示了该架构的卓越性能:一个160M参数的小型语言模型,结合一个18M参数的记忆单元和来自4.6B记忆库的动态调用支持,其性能与传统架构中参数量超过两倍的模型相当。此外,研究也表明分层前馈记忆在各种Transformer架构下具有高度鲁棒性,无论是在预训练阶段添加还是后续加载,都表现出显著的适应性。

在移动端等计算资源受限的环境中,语言模型的微调无疑是一项技术挑战。即使是局部参数调优(如 LoRA),其内存消耗也远高于推理阶段,常被认为在边缘设备上难以实现。
研究团队在此背景下,探索了通过低内存优化方法微调大模型的可能性。尽管零阶优化(Zeroth-Order Optimization, ZO)能显著降低内存需求,但其收敛速度较传统的反向传播慢10倍至100倍,限制了可用性。这突显出在资源受限环境中,进一步优化内存高效的反向传播方法的重要性。
在 2024 年 NeurIPS 上的 “现代机器学习微调:原则与可扩展性”(FITML)研讨会上,研究团队提出了一种基于蒸馏的记忆保持微调方法,作为语言模型后续学习的有效解决方案。
大规模预训练模型往往包含丰富的世界知识,但为了满足特定任务需求,通常需要进行能力强化或对齐训练(例如数学推理、自然语言理解)。蒸馏式微调方法通过保留预训练模型核心知识的同时,实现对新任务能力的精准增强,使语言模型能够快速适应并获得优秀表现。
无论是通过引入层级记忆架构,探索移动端环境下的高效微调,还是开发更为灵活的微调策略,这些研究皆表明,语言模型领域的进步不仅依赖于模型规模的增加,更在于如何有效平衡性能、计算成本与适配性。
这一系列成果,无疑为机器学习领域的技术实践开辟了新路径,也为更广泛的应用场景带来了无限可能。随着研究的深入,分层记忆与高效技术可能成为未来模型优化的重要趋势,引领人工智能迈向更加灵活与智能的未来。



[人形纪元网出品] [大规模预训练模型] [语言模型微调] [层级记忆架构] [低内存优化] [刘智勇频道] [RoboPony(真机智能)] [真机算法] [PixStock.online(设计智能体图库)] [ZhenMeta.com] [机器姬永生人] [机器洞察网] [AI之星网] [风投高科网] [猛虎财经网] [硅基科学网] [人形纪元网] [真机量化(zhenquant.hk)] [真机内参] [高能判官] [片场狂徒] [暴徒外放] [Cognition OS] [Embodied OS] [黄金广告位]
📚 【精品资源】添加关注『人形纪元网微信公众号』,即可免费获取完整版《刘智勇频道第五卷》