



苹果公司研究团队近日在CVPR 2025大会上分享了最新研究成果——FastVLM,一种面向高分辨率图像设计的高效视觉语言模型。该模型解决了视觉语言模型(Vision Language Models,以下简称VLM)在准确性与效率之间长期存在的技术瓶颈,展现出强大的实时性能与适配能力,尤其适合隐私保护场景中的设备端应用。


视觉语言模型在结合视觉和文本理解方面具有广泛应用,如无障碍助手、用户界面导航、机器人技术及游戏开发等。然而,在提升模型准确性的同时实现高效推理一直是技术上的难点。VLM 的准确性通常随着输入图像分辨率的提高而增强,这在需要细粒度内容理解的任务中尤为重要,例如文档分析和图像问答。然而,高分辨率图像处理会显著增加视觉编码器的处理时间和生成的视觉令牌数量,最终导致时间延迟加剧,降低实时性能。
面对这一技术难题,苹果研究团队提出了新的解决方案——FastVLM,以其简洁而高效的设计在准确性和延迟之间找到了最佳平衡点。
FastVLM基于一种混合架构视觉编码器——FastViT-HD,专为高分辨率图像处理优化。相比传统的视觉编码器,它能够生成更少但质量更高的视觉令牌,从而减少大模型(LLM)的预填充时间。FastViT-HD结合了卷积和Transformer模块,包括卷积嵌入层、多尺度池化及额外的自注意力层,使其既能够保持高精度图像处理性能,又能显著降低处理延迟。
FastVLM 的架构设计还引入了一个简单的多层感知器(MLP)投影模块,用于将视觉令牌映射到 LLM 的嵌入空间中。在对不同尺寸的 LLM 进行整合测试后,研究团队验证了这一设计的优异性能,其在平均准确性和推理时间上的表现显著超过现有主流模型。


研究表明,FastVLM以高效性和准确性为特点,在多个基准测试中均表现优秀。在“时间到首令牌”(Time-to-First-Token,简称TTFT)方面,FastVLM在高分辨率场景下可以显著减少延迟。在与其他流行视觉架构进行对比时,FastVLM不仅速度更快,还能保持更高的任务准确性。例如,其运行效率比ViT-L14快20倍,模型体积缩小了约8倍。
FastVLM 的优越性能得益于其融合了视觉编码器的创新架构与精准的设计优化,避免了复杂的令牌裁剪或合并技术。同时,研究团队提出了一种动态平铺(Dynamic Tiling)的补充方法,可以在极高分辨率场景中进一步提高模型性能。
FastVLM的高效性使其能够在设备端实现近乎实时的视觉查询处理,这为隐私保护场景中的人工智能应用提供了坚实基础。例如,苹果团队展示了一款基于FastVLM的iOS及macOS演示应用,成功实现了在iPhone设备上的本地GPU推理功能。这一成果标志着VLM技术的新突破,有望为移动设备用户带来更加智能和便捷的交互体验。
此外,FastVLM 的开发为其他视觉语言模型的优化提供了重要参考,同时推动了高分辨率图像处理领域的学术与行业进展。
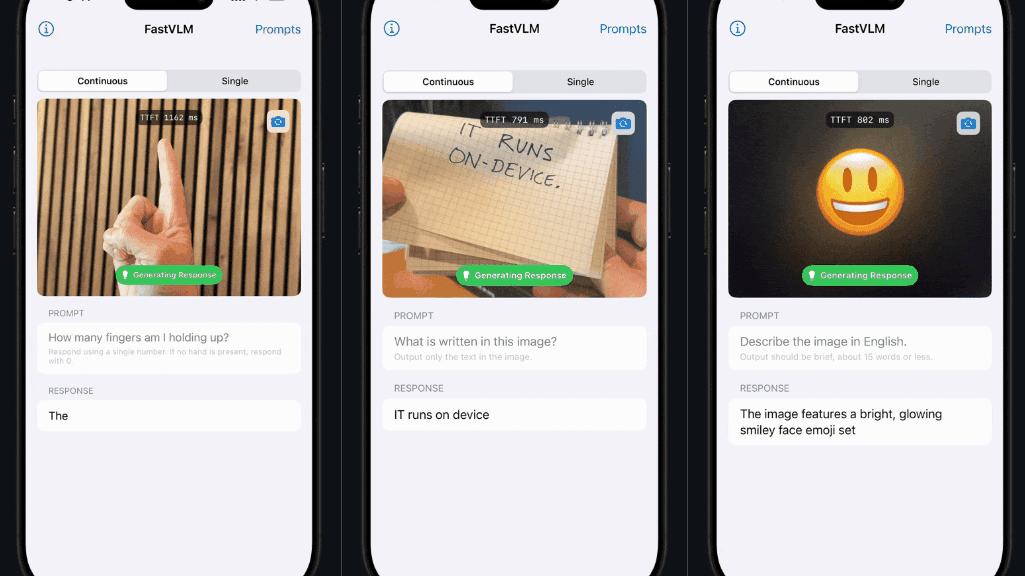

通过结合视觉与文本的理解能力,视觉语言模型可支持多种实际应用。然而,准确性与效率的权衡问题曾长期制约模型在实时应用中的落地表现。FastVLM成功打破这一限制,凭借其混合架构视觉编码器FastViT-HD,实现了高准确性与高效率的统一,展现了强大的技术前景。
随着FastVLM的发布,苹果公司展示了其在机器学习领域的卓越创新能力,也为实时设备端人工智能技术的未来发展注入了新的动力。CVPR 2025大会上的亮相进一步印证了苹果在人工智能基础研究与实践应用中的领导地位。


[人形纪元网出品] [高效视觉语言模型] [高分辨率图像处理] [苹果FastVLM架构优化] [实时设备端人工智能] [刘智勇频道] [真机智能] [机器姬智能体] [机器洞察网] [AI之星网] [风投高科网] [猛虎财经网] [硅基科学网] [人形纪元网] [黄金广告位]
📚 【精品资源】添加关注『人形纪元网微信公众号』,即可免费获取完整版《刘智勇频道第五卷》